

Introduction
Before we introduce the theory, terminology and methods of machine learning, let’s start by explaining what is machine learning and what isn’t. The categorisation of machine learning can often be misleading. ML is undeniably one of the most influential and powerful technologies in the modern world. There is no doubt, it will continue to be popular headlines for future. In this article we will introduce machine learning concept for data science application, covering fundamental concept without digging in high level mathematical background.
Basically, machine learning for data science involves building mathematical models to get insight of data, once the model has been fit to introduce seen data, it can be employed to predict and understand newly observed data. It’s a tool to turn information into knowledge. A huge portion of data can take a long time for human to process and find out the pattern hidden within. On the other hand, ML models are techniques to find the insight of undelying pattern with mass data automatically.
We interacted with ML every single day. Every time we shop, listen to music, watch movies, ML is the technology behind it, continuously learning and improving from every action. More philosophically, this learning is similar to learning by the human brain.
Methods
ML can be categorised in multiple forms. At the most fundamental level, ML can be formed into two types; supervised learning and unsupervised learning. In addition to this, there are so-called semi-supervised methods. They are ML methods often practical when incomplete labels and introduced. This article covers general concepts and techniques. To make these ideas more concrete, we will look few examples of ML tasks.
Classification: Predicting discrete specimens
Let’s take a look at a simple classification in which you are given a set of labelled data, and you aim to create a model and use this moded to classify some unlabelled data. Imagine we have the data set shown in the figure below.

We have two features represented by (x,y) on the plane, which means we have two class labels. From these features and labels, we like to create a model which will predict new points. There are a number of models for such a task, but since our aim is to explain the concept, we will use a simple approach that separates two different groups of points.
Imagine adding a line between plane. Each time new data is detected, it will fall into the side of the most similar group based on model parameters that describe the location and orientation of the line for our data set.
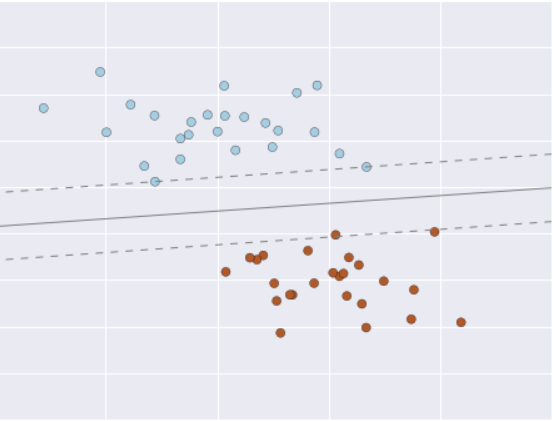
Now, this model has been trained, and it can be generalised to new unlabeled data. It means we can use new datasets, draw this line through and assign a label to new samples based on the trained model.
Regression: Predicting continuous labels
In contrast with the discrete labels of a classification algorithm, we will next look at a simple regression task in which the labels are continuous quantities.
Consider the data shown in the following figure, which consists of a set of points each with a continuous label:
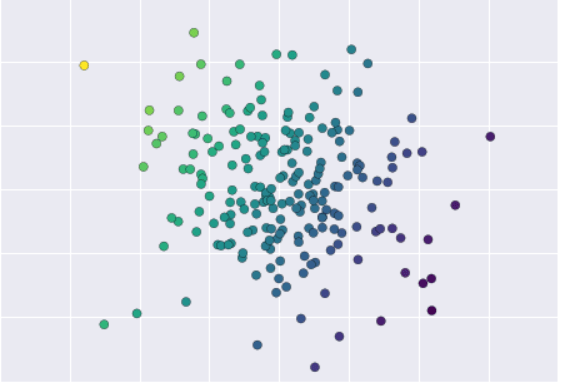
There are a number of possible regression models we might use for this type of data, but here we will use a simple linear regression to predict the points. This simple linear regression model assumes that if we treat the label as a third spatial dimension, we can fit a plane to the data. This is a higher-level generalisation of the well-known problem of fitting a line to data with two coordinates.
Some important regression algorithms are linear regression (see In Depth: Linear Regression), support vector machines (see In-Depth: Support Vector Machines), and random forest regression (see In-Depth: Decision Trees and Random Forests).
Summary
Here we have seen a few simple examples of some of the basic types of machine learning approaches. I hope this section was enough to give you a basic idea of what types of problems machine learning approaches can solve.
In short, we saw the following:
- Classification: Models that predict labels as two or more discrete categories
- Regression: Models that predict continuous labels
In the following sections we will go into much greater depth within these categories, and see some more interesting examples of where these concepts can be useful.
